ChatGPT 一 通用人工智能时代的奇点
Liber 2023-07-26 18:23
火爆的AIGC
- ChatGPT, MJ, SD, ElevenLabs, DID
- 最快的从0到1亿用户的应用
- 最大化个人能力的时代
- 巨头战略转型
OPENAI公司
- Sam Altman & Elon Musk等
- 2015年,防止Google垄断
- 非营利性机构,承诺将所有技术开源,Sam 0股份
- 2019 Sam创立OpenAI LP,LLC to LP实现了资本和智力的分离
- CTO Mira Murati(生于 1988 年)“发布产品是了解人们如何使用和滥用技术的唯一途径”
OPENAI公司 - 四个阶段

把公司租给微软,租期取决于公司的赚钱速度
语言模型的发展
NLP自然语言处理的发展
- 1950s 图灵测试
- 1970s 语义和语法规则
- 1990s 基于统计的方法(终于把基于逻辑规则的问题转化成了一个数学问题)
- Today 深度学习 + 数据驱动
基于统计:通过分析大量的语言数据,来推断和预测语言现象,为自然语言的上下文相关性,来建立数学模型(利用马尔科夫假设转化成二元模型Bigram Model,范式:N-gram Model)
优点:泛化性、更好的容错性
数据驱动的语言模型的里程碑
- N-gram Model、Bag-of-words 词袋等
- Neural Probabilistic Language Model (2003 Yoshua Bengio) :以神经概率语言模型来建模,即用神经网络来学习单词间的复杂关系,激活了一系列后面的神经网络模型:RNN、LSTM
- Word2vec:词向量,一种简单高效的分布式单词表示方法(把单词通过神经网络变成向量表示;相关的词,在向量空间中的距离应该更近)
- Pre-trained Language Model (2018年之后):基于transformer架构的预训练语言模型,采用更大的语料库和更深的神经网络进行预训练和微调
循环神经网络 - RNN, LSTM
- Transformer之前的 SOTA (state of the art)
- 可以看做链式结构,在网络中引入了时间维度(每个时间步都有个隐藏状态保存时间信息),使信息能够在神经网络中进行循环的传递
- 实现了一个长序列中信息的持续传递和记忆的功能
预训练模型(Pre-trained Language Model)
- 无监督学习:互联网语料,掩码
- 微调以适应下游任务:根据下游任务(文本分类如情感分析、问答、命名实体识别等),用提供的小数据集进行微调(体现出了强大的迁移学习能力,比CV模型的迁移学习效果好)
 (OpenAI的GPT-3黑盒微调)
(OpenAI的GPT-3黑盒微调)
预训练模型 - 微调(BERT)
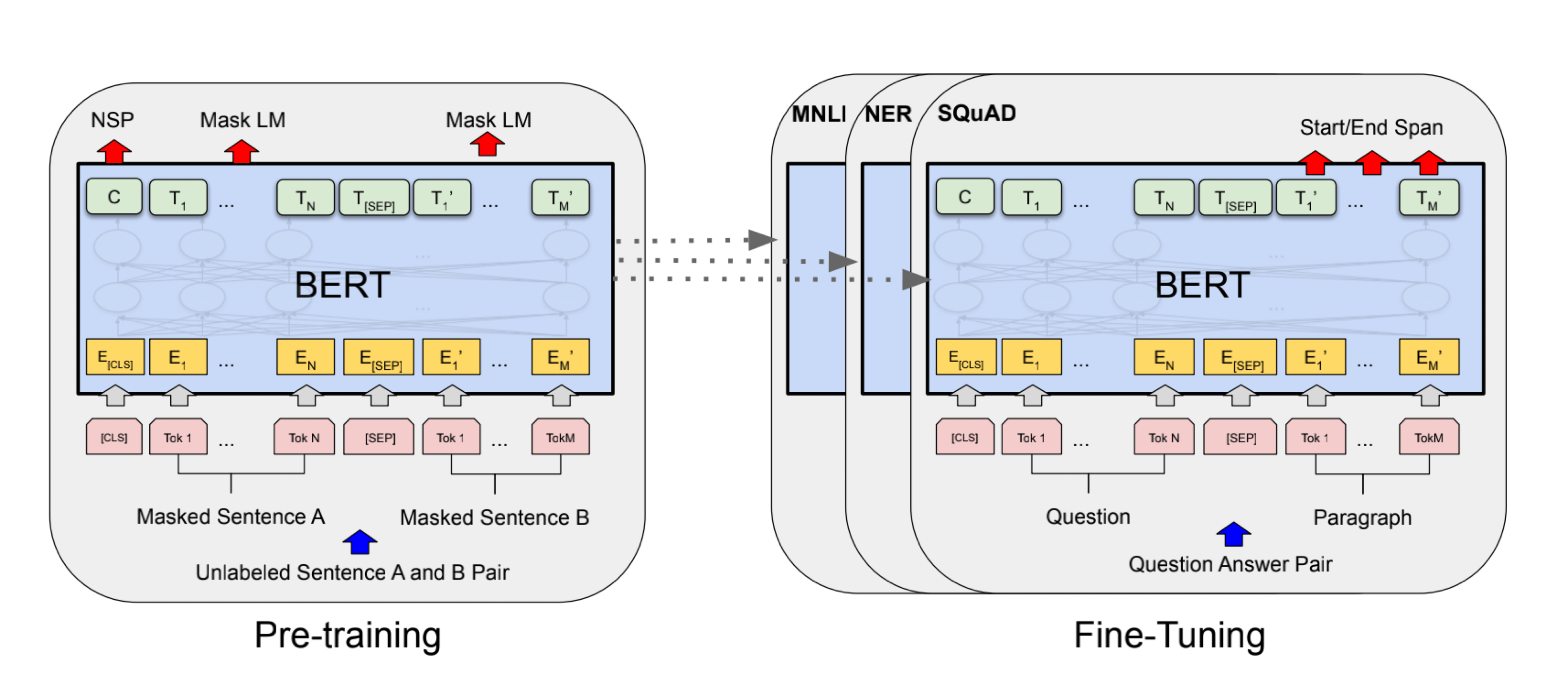 (分类器最关键的任务是要在答案这块要标上这个是答案、是答案、是答案)
(分类器最关键的任务是要在答案这块要标上这个是答案、是答案、是答案)
Transformer架构
- Google 2017
- 解决传统序列模型(RNN循环神经网络)存在的效率和并行计算的问题
- 在训练速度(不需要像RNN那样循环递归的回访过去的数据,而是做整体的并行处理)和上下文捕捉(注意力机制)的性能表现更优秀
- 堆叠多个层来构建深度学习模型
Transformer架构 - 编码器解码器
Seq2seq: 输入的文字经过深度神经网络的处理,输出合适的回答
编码器:
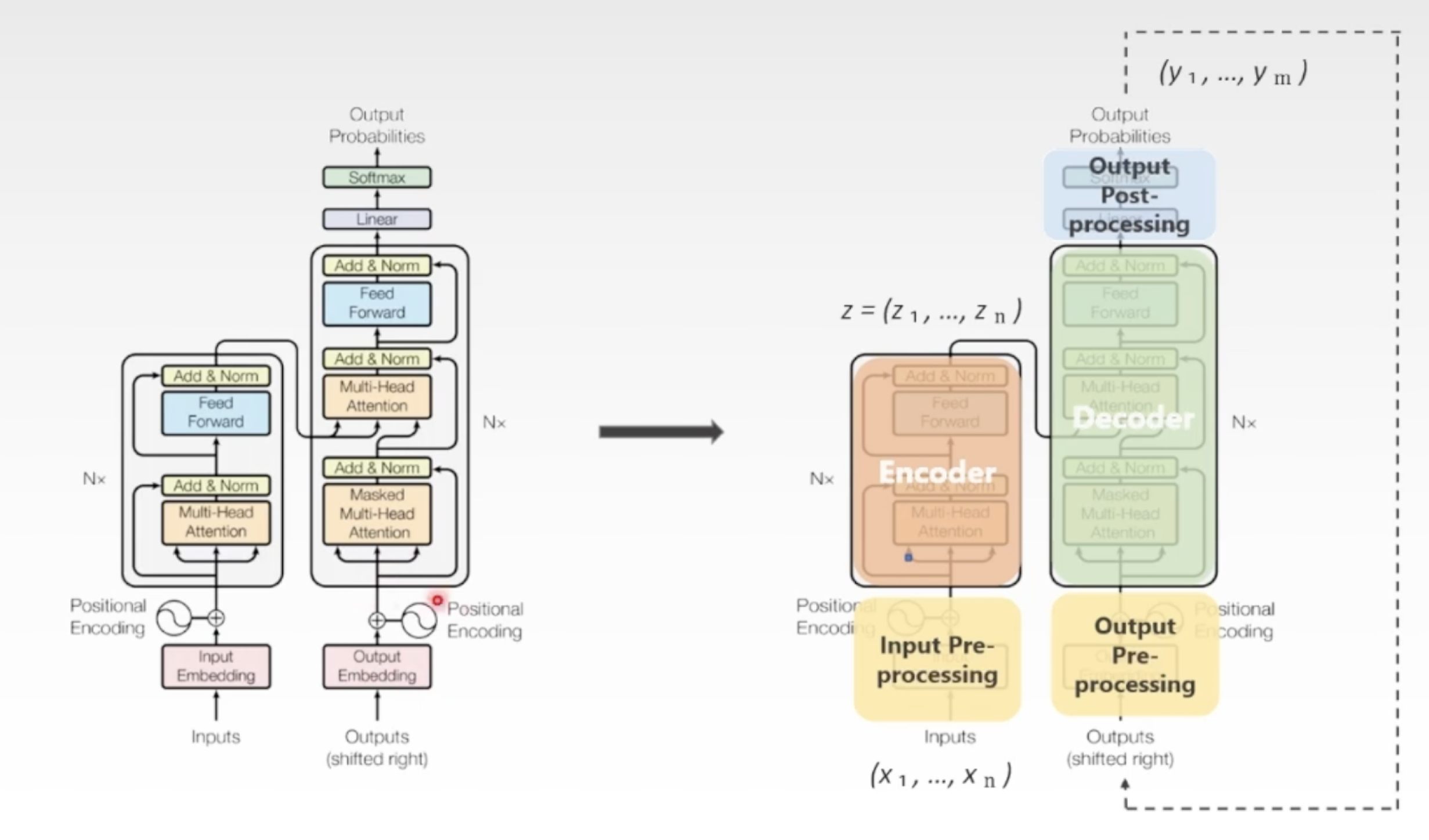
先是把输入的符号,输入序列进行一个符号表示x1-xN 映射成embedding向量,同时加入序列位置,然后一起进入编码器的主处理单元:
- 对输入向量做多头自注意力的处理,这个就是为了让模型学习序列的整体信息
- 全连接前馈网络(即传统神经网络中的前馈网络,将注意力机制的结果进行线性变化和归一化等操作,以提取更丰富的语义信息)
当输入序列经过编码器的处理之后,形成了已经习得全局上下文信息的一个新的embedding序列
解码器:
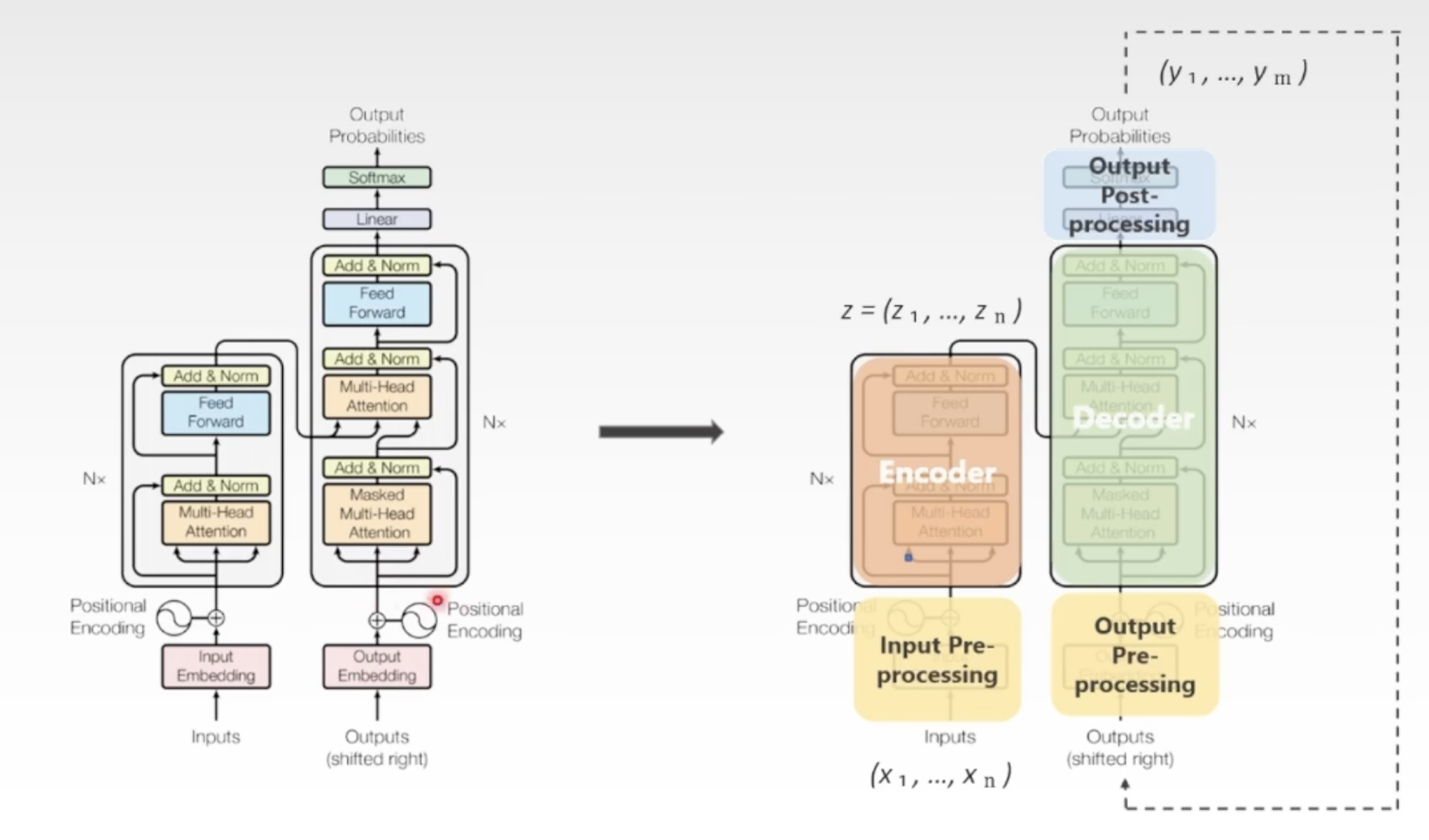 (Nx: 串联相同结构的多个编码器和解码器,形成深度的神经网络)
(Nx: 串联相同结构的多个编码器和解码器,形成深度的神经网络)
- 带掩码的多头自注意力机制,是在解码器每次输出的向量上迭代进行的,即解码器一次只生成一个输出元素,先输出y1,然后把y1传回来传给自己然后再去解码生成y2(自回归机制)效果就是蹦字;掩码是防止模型在生成每个词时看到输入序列之后的信息,所以要mask上,比如翻译的case
- 读入了编码器输出的embedding序列z,加上自己输出的y1,y2,整体再做多头注意力,叫Encoder-Decoder Self-Attetion,把它们结合起来,就有了全局信息(整合了编码器的全局信息和解码器输出的向量)
- 全连接前馈网路
Transformer架构 - 注意力机制
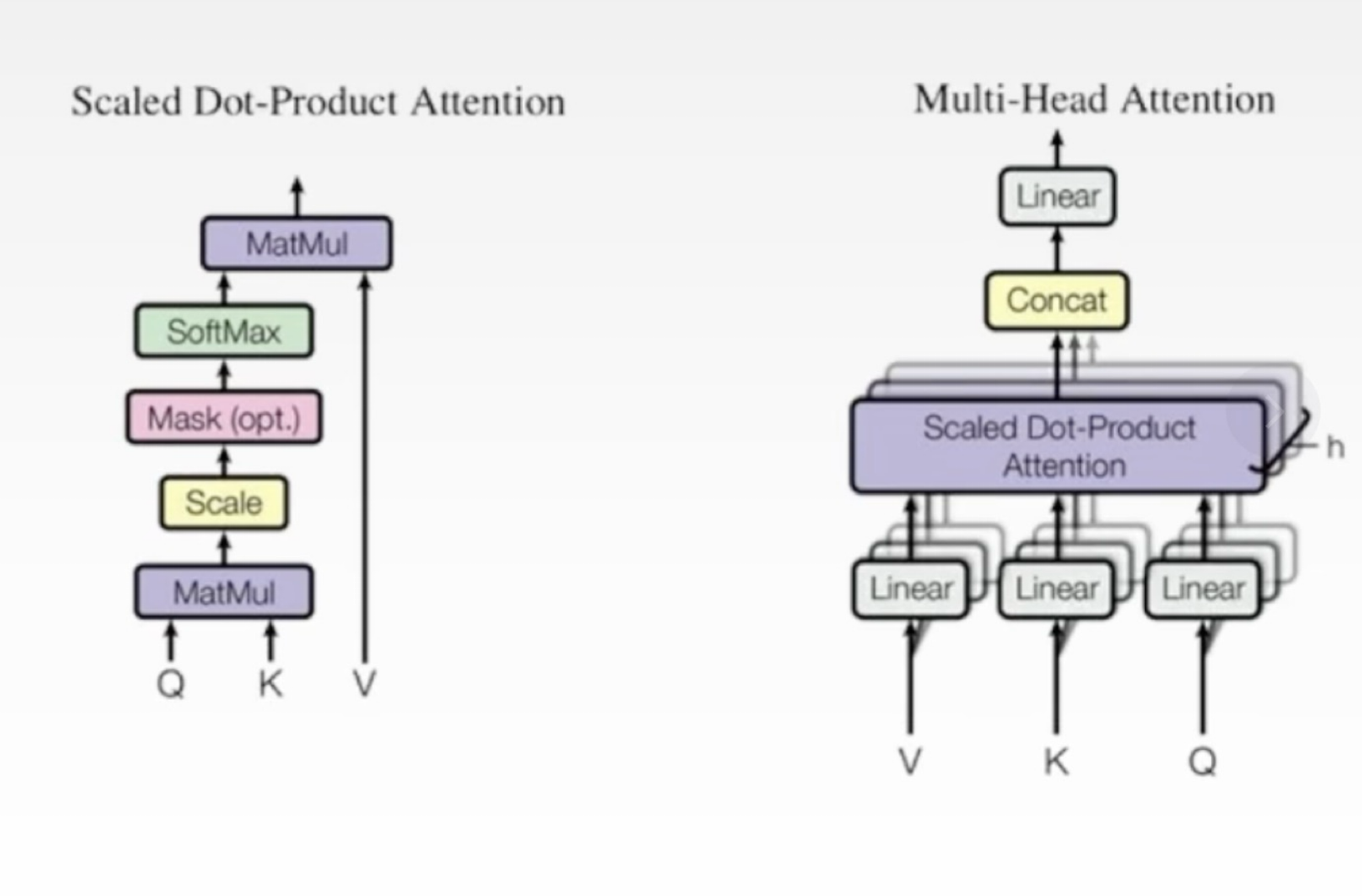 (缩放点积注意力)(多头注意力)
(缩放点积注意力)(多头注意力)
- 处理序列的技术,让模型更加关注一个序列中更重要的部分(会输出的权重)而传统的RNN在每一步都会等同处理)
- 计算输入序列中的每一个单词和其它单词的关联程度,关联程度高,相应的权重就高,这样模型就能够更好的理解输入序列的语义信息
- 多头注意力机制:通过矩阵的计算,生成多个注意力头,然后学习不同层次的注意力权重,从而进一步提高模型的表达能力它每一个注意力头,捕捉到的可能都是一个更特定的一种相关性,因为语言它是复杂的,一个词可能跟其它的词相关有很多个维度,所以用多个头一起计算,那么各种各样复杂的表征和相互的关联就全部被深度神经网络给捕捉到了
注意力机制是由三个部分组成:
- Query, Key, Value:查询键值,机制输入进去的是一个序列,每一个元素都是一个向量,词向量,对于每一个元素我们都会给它计算出来三个向量,query, key, value(通过序列本身的词向量 乘以 query, key, value的参数矩阵,通过矩阵乘法,我们从词向量本身,衍生出来三个额外的向量query, key, value)
- Attention Scores,注意力的得分:对于每个查询向量,我们都要计算它和所有其它键向量之间的相似度得分,这个得分我们叫它注意力得分(通过查询向量和键向量进行点击dot product计算得到的)
- Attention Weight,注意力的权重:我们得到了注意力得分之后,它会通过softmax进行一个归一化,然后就得到了注意力的权重,这个权重,实际上就是每个值向量的加权平均值,也是自注意力机制的输出
Transformer架构 - 位置编码(Positional Encoding)
为什么需要位置编码?
- RNN中不需要记录单词是在一个序列中的位置编码,因为它是通过循环记忆去来捕捉一个单词的位置信息,但是在Transformer中,不存在那种循环机制,所以说它就要同时输入这个positional encoding,然后来把单词本身的嵌入还有在序列中的位置一起输入注意力机制,才能够计算出来单词和单词中的联系
- 词嵌入它的内涵是通过编码来蕴含单词本身的语义信息,本身确实是没有序列位置信息的,所以必须要结合上下文,同时要结合一个词在一个序列中的位置信息,它才能够把这个字和其他位置的token给关联起来
位置编码可以有效的处理各种长度的序列,它也不需要一直进行循环,是一个并行的计算
经典预训练模型 BERT vs GPT3
- BERT: Bidirectional Encoder Representations from Transformer
完形填空、判断是不是下一句
只需设置编码器:把序列输入进去,自动做完形填空,所以说它并不需要去生成文本 - GPT3: Generative Pre-trained Transformer
单向自回归的训练方式
只保留单向的解码器部分:减少了模型的参数数量和负责程度,也就意味着能够采取更大的模型规模和更深的网络结构来捕捉文本中的复杂特征和语义信息
GPT模型家族
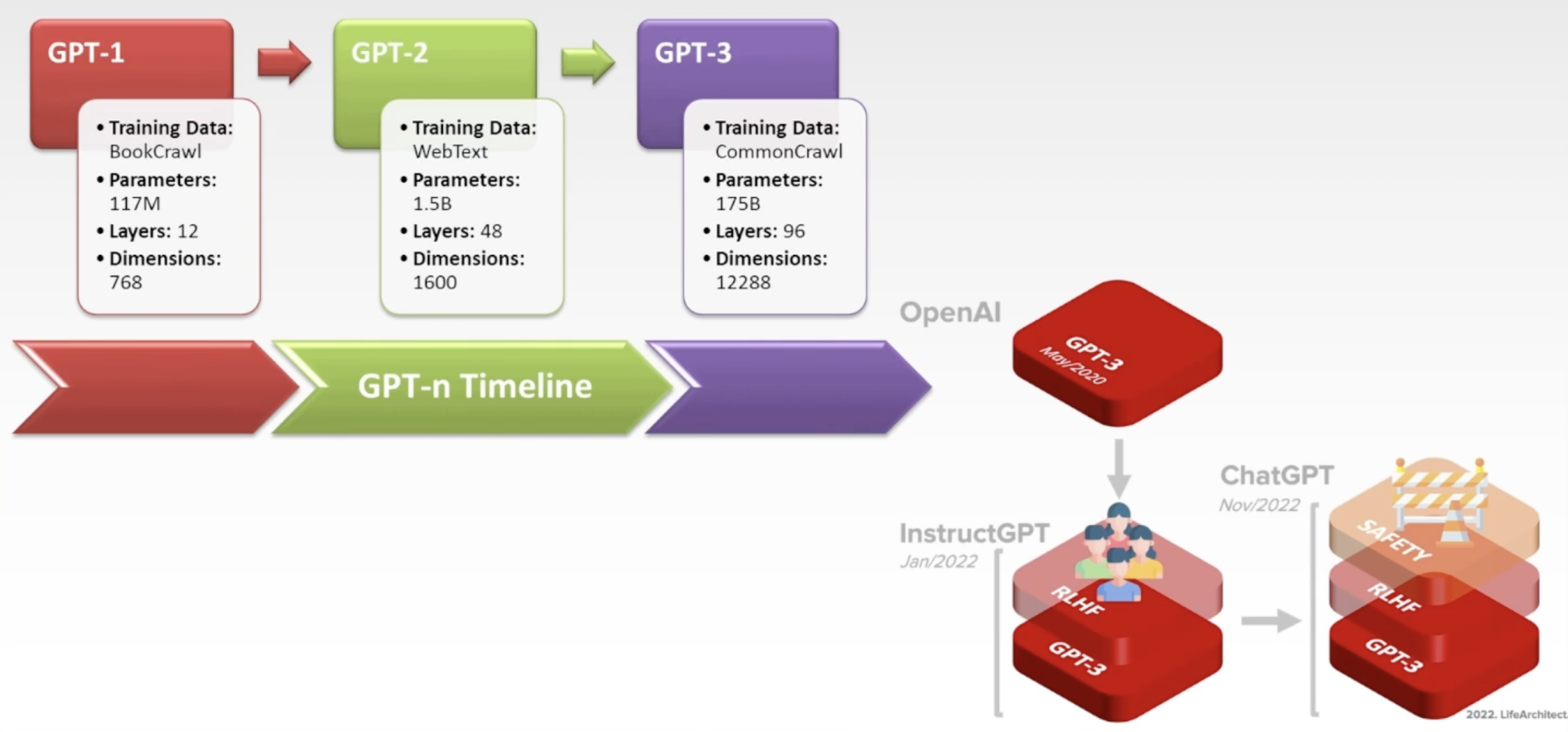
GPT3模型家族
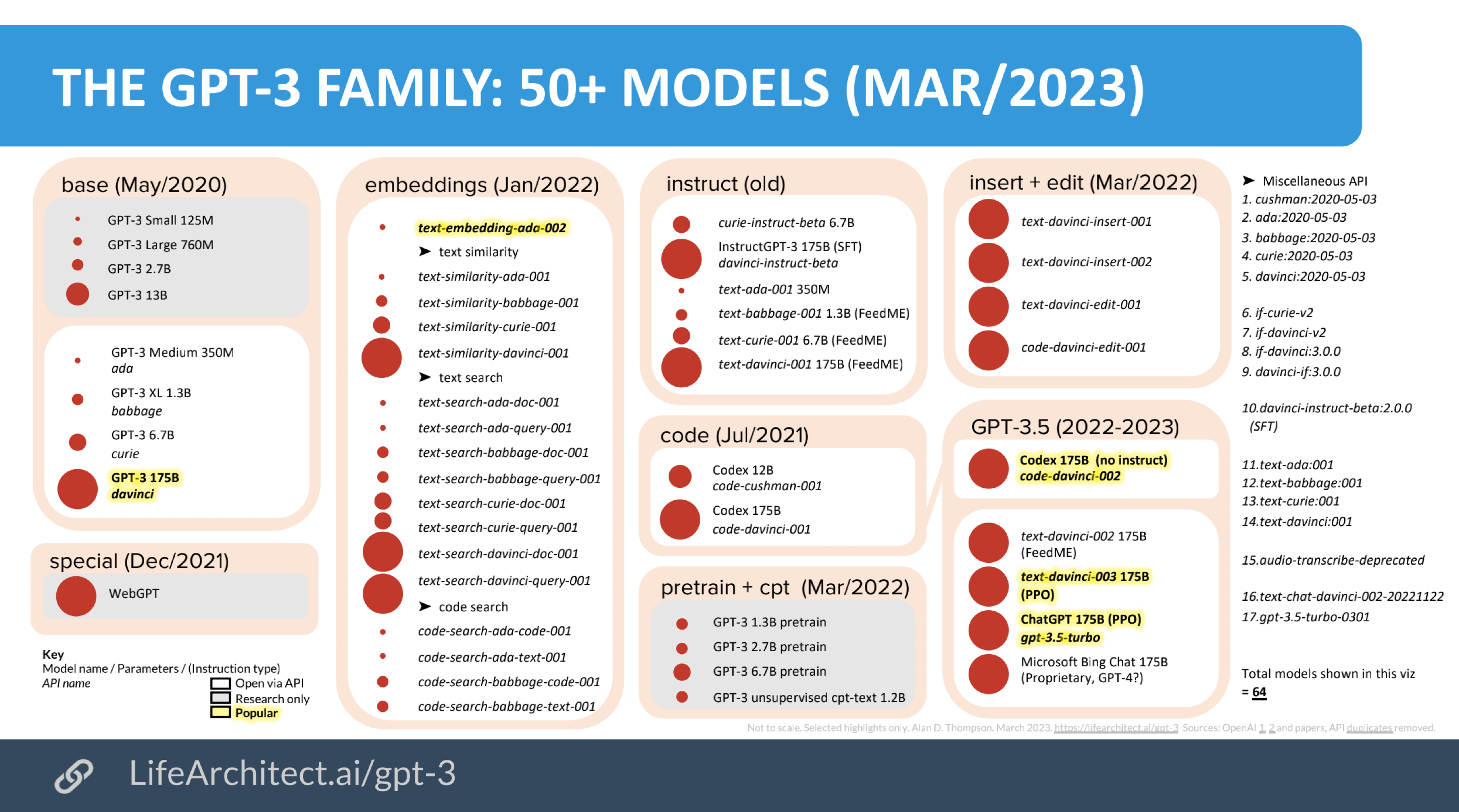
从GPT到ChatGPT
- GPT-3.5: 万亿词汇量通用文字数据集
- 微调:基于人类反馈的强化学习RLHF(human feedbacked reinforced learning),让它更了解人类想听什么
- InstructGPT + Safety Layer
- 技术 + 产品 + 商业的结合
- 从GPT到ChatGPT的演进,是一个从通用nlp模型到特定任务的聊天机器人的迁移,需要对模型进行很多的微调和优化
- 文本和代码同时训练,两个系列的融合
- UI良好的设计和交互
- 按商业节奏发布产品和新功能
基于人类反馈的强化学习(RLHF)
三个步骤:
- 有监督的训练:手工标注合适的问题及其答案,让GPT在这个基础上进行泛化,提供方向上的引导
- 训练奖励模型:采样一个提示和多个回答输出,手工标注出所有输出的优劣(打分),该数据应用于训练奖励模型
- 强化学习(根据分数调参):不断地试错过程中,自我调整优化策略,最大化预期的长期奖励
其它的模型
- T5: Google开源,同时设置编码器和解码器,训练比较难
- PaLM: Google 540B Pathways language model. Pathways 是一种新的ML 系统,可以跨多个TPU Pod 进行高效训练。
- Claude: Anthropic 目标是颠覆现有的深度学习范式 OpenAI前研究副总裁创建,RLHF的实现与ChatGPT有些不同
新思路:通过Prompt直接使用大模型
- 有了足够好的大模型之后,不需要进行微调,直接向模型提供一些提示文本,模型直接生成答案
- 结果好不好,取决于会不会提问
- Prompt Engineering是一门学科
- CoT, Chain of Thought: 利用模型的推理能力,允许模型将问题分解成多个步骤,构造思维链典型用法:Zero-shot CoT: “Let’s verify step by step”
- ToT, Tree of Though: 在每一个步骤中,生成多个答案,每一步都从中淘汰掉差的答案,最终找到最好的答案(一般都是多轮对话)也有人提出了single prompt的用法:A sample ToT prompt is: “Imagine three different experts are answering this question. All experts will write down 1 step of their thinking, then share it with the group.Then all experts will go on to the next step, etc. If any expert realises they’re wrong at any point then they leave.The question is…”
面向大模型编程
- LlamaIndex, Llama Hub
- LangChain (LangChain已经是面向大模型开发的事实上的标准了?)
- AutoGPT
岗位需求:
- 不做底层基础大模型
- 中间层,如LangChain
- 偏应用层,有AI经验的各方面都行,小公司,需要业务上know how的人
Hugging Face - The ai community building the future
- 一个用于NLP的python库
- 提供了预训练的语言模型和工具,使得使用者可以轻松训练,使用共享最先进的NLP模型
- 提供了方便的API
- 不仅提供模型,还提供Dataset下载
Hugging Face - Models
- Base Models
- 包含具体的NLP任务处理头的
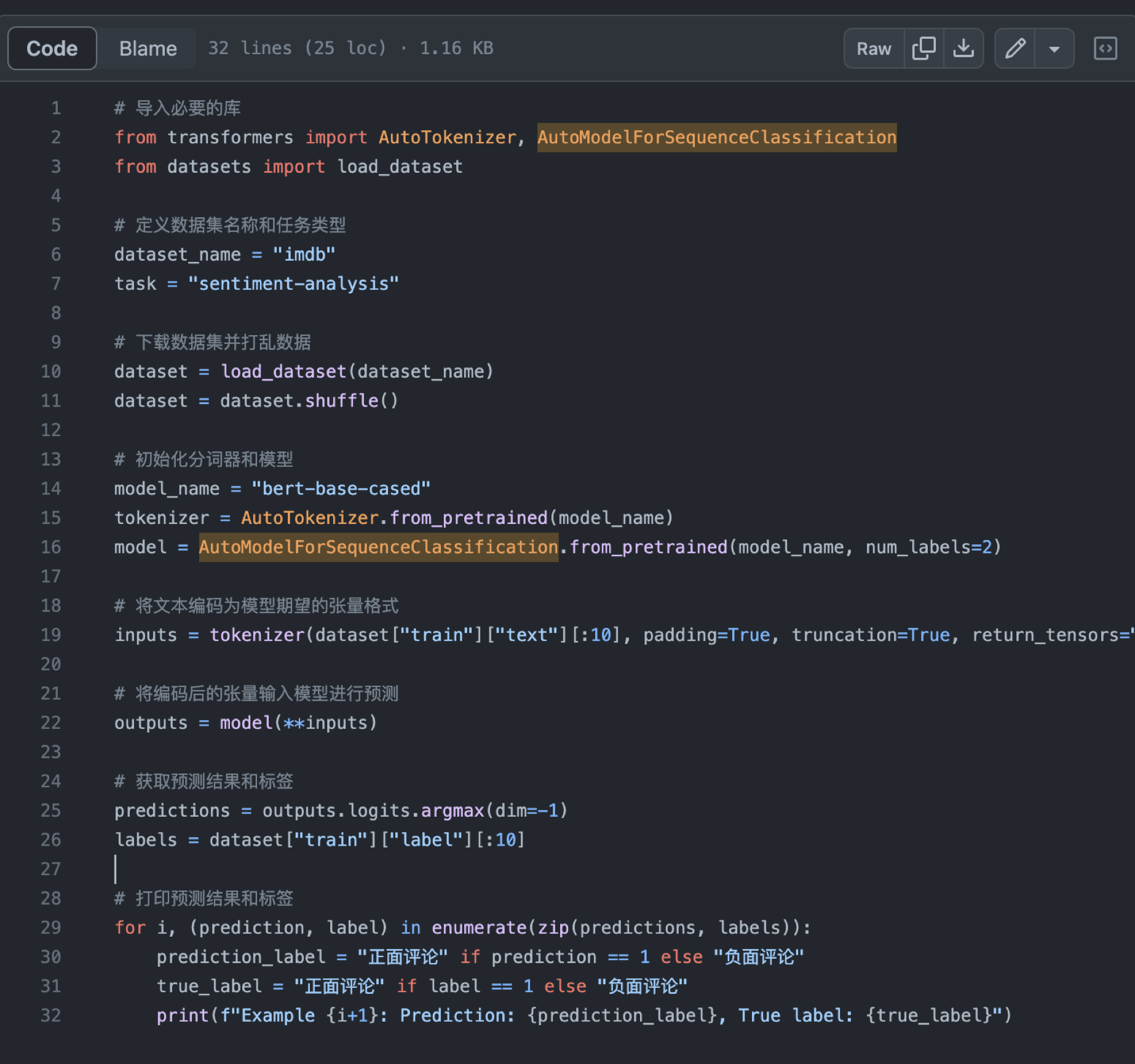 用IMDB数据集做影评情感分类(使用的auto二分类模型,只用了影评的数据,没有进行微调,准确率一般)
用IMDB数据集做影评情感分类(使用的auto二分类模型,只用了影评的数据,没有进行微调,准确率一般)
Hugging Face - 微调BERT
 (用指定数据集微调训练BERT)
(用指定数据集微调训练BERT)
Hugging Face - 重要组件
- Hugging Face Dataset
- Hugging Face Tokenizer
- Hugging Face Transformer
- Hugging Face Accelerate:加速深度学习的工具库,只需要几行代码就可以在多个GPU和TPU(Tensor Processing Unit)之间高效的分配计算资源,可以实现更快的训练速度和更好的训练效率
云GPU
- Colab: a hosted Jupyter Notebook service that requires no setup to use and provides free access to computing resources, including GPUs and TPUs.
- Inference API:Colab 能加载的模型比较小,对于大一点的模型就可以试试 Inference API。它是 HuggingFace 免费提供的,让你可以通过 API 调用的方式先试用一些模型。(有些模型可以看看有没有提供免费的HuggingFace Space)
- Inference Endpoint:Inference API 只能给你提供试用各个模型的接口。因为是免费的资源,自然不能无限使用,所以 HuggingFace 为它设置了限额(Rate Limit)。如果你觉得大模型真的好用,那么最好的办法,就是在云平台上找一些有 GPU 的机器,把自己需要的模型部署起来。HuggingFace 自己就提供了一个非常简便的部署开源模型的产品,叫做 Inference Endpoint。你不需要自己去云平台申请服务器,搭建各种环境。只需要选择想要部署的模型、使用的服务器资源,一键就能把自己需要的模型部署到云平台上。
多模态模型
- OpenAI CLIP: 多模态模型
这个模型是通过互联网上的海量图片数据,以及图片对应的 img 标签里面的 alt 和 title 字段信息训练出来的。这个模型无需额外的标注,就能将图片和文本映射到同一个向量空间,让我们能把文本和图片关联起来。
场景:- 图片的零样本分类(家具、动物)
- 通过 CLIP 进行目标检测(识别猫)
- 商品搜索与以图搜图
- DALL-E: 文生图、通过上传蒙版来编辑和扩展图像、生成给定图像的变体
- Midjourney
- Stable Diffusion: 完全开源、文生图、图生图、提升图片的分辨率CIVITAI: 分享Stable Diffusion模型的平台Stable-Diffusion-Web-UI: 使用各种SD模型的权重文件把 Web-UI 在本地部署起来,它会提供一个图形界面让你不用写代码就可以直接调整各种参数来生成图片
- ControlNet: 基于SD实现更精细的控制- 通过边缘检测绘制头像- 通过“动态捕捉”来画人物图片- Scribble: 基于ControlNet的模型,以一个简单的简笔画为基础,生成精美的图片
- Visual ChatGPT: 边聊边画
LangChain 的 ReAct Agent 模式:- 把各种各样图像处理的视觉基础模型(Visual Foundation Model)都封装成了一个个 Tool
- 将这些 Tool 都交给了一个 conversation-react-description 类型的 Agent。每次你输入文本的时候,其实就是和这个 Agent 在交流。
- Agent 接收到你的文本,就要判断自己应该使用哪一个 Tool,还有应该从输入的内容里提取什么参数给到这个 Tool。这些输入参数中既包括需要修改哪一个图片,也包括使用什么样的提示语。这里的 Agent 背后使用的就是 ChatGPT
- 最后,Agent 会实际去调用这个 Tool,生成一张新的图片返回给你。
结语
“就如同黑洞的奇点,通用人工智能的时代是无法预测的未知领域,但我们探索它并不是为了预见未来,而是为了用智慧塑造我们希望的未来。” – ChatGPT